What is Pre-Cache?

Pre-caching involves proactively caching resources on the CDN network so that they are readily available for users before they visit a web page or use an app. This technology streamlines the loading process, allowing users to access what they need quickly and eliminating the need for the first cache HIT.
Pre-caching is available for our Reseller Hosting customers, who can activate it through the Website Turbo add-on, and for our Autoscale Hosting customers.
The Benefits of Pre-Caching
Pre-caching comes with numerous benefits, including:
- Improved Load Times: Pages and applications can load significantly faster by storing resources in advance.
- Enhanced User Experience: Faster load times and smoother interactions improve user experience.
- Efficient Bandwidth Use: Pre-caching can reduce unnecessary bandwidth usage by minimising the need to fetch the same resources from the server repeatedly.
- Reduced Server Load: Pre-caching aids in distributing the load across servers.
In My20i, you can access a Cache Report that shows you the pages we've identified, whether they are cacheable, and if they are not, the reasons why.
Using the Cache Report
Precaching allows for your websites to be pre-fetched by all of our CDN locations around the globe, for faster response times from anywhere in the world.
In My20i, you'll receive access to a new Cache Report that will display what pages are and are not cacheable on your sites.
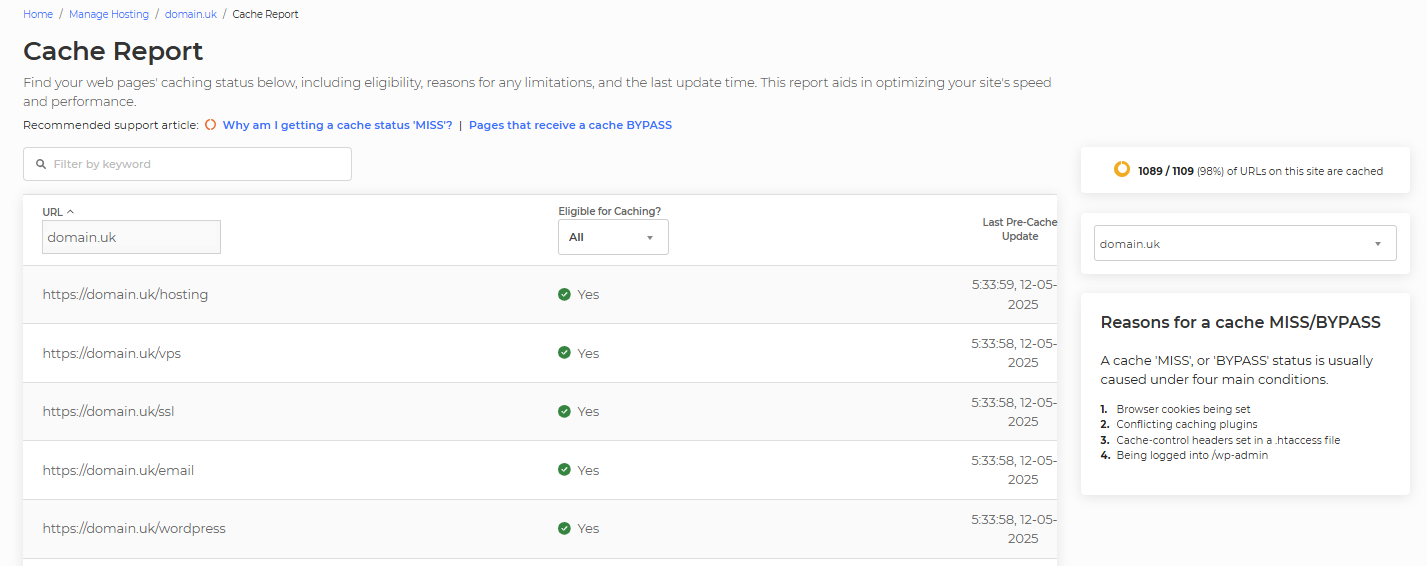
If a page is found to be unable to be cached, you’ll be informed of the reasons why, providing a very easy way of identify and resolve caching issues across your website to give it the absolute maximum performance.
Pre-caching ensures a much higher cache hit rate for all users regardless of location and thus a faster experience for your visitors.
How does Precaching work?
To pre-cache your site, our 20i web crawler navigates each URL on your site and caches it. The cache report displays the URLs that were crawled and whether they were successfully cached.
Pre-caching has a limit of 1,000 URLS; however, you can control which URLS get crawled by creating a blocklist. To exclude specific URLs from being crawled, you need to make a .crawlrc file in your website's root directory.
By default, if you do not have a .crawlrc file, we exclude the following paths:
/nonce /basket /share
/wishlist /cart
/yith /wcanThe .crawlrc file contains a list of the paths you want to exclude from crawling. It must be a valid JSON file formatted as follows:
{
"SKIP_REGEX": "/basket|contact|cart/"
}
The only key should be SKIP_REGEX, and the value should be a combination of paths to be excluded from your site. You can use regex, where the `|` symbol separates multiple paths. In the example above, we excluded /basket, /contact, and /cart from being crawled.
With the .crawlrc file, you have greater control over what URLs get crawled on your site.