4XX errors cover a range of HTML errors that usually occur when a file that is attempting to be accessed cannot be found, has incorrect permissions or is inaccessible by the person loading it.
The causes can range from a simple typo in the URL to security rules restricting users from entering certain areas. Identifying the specific type of 4XX error can help you to understand the cause, who is impacted, and how to fix the error.
Types of 4XX Error
4XX errors have four main types that are commonly encountered, each with their own sub-header that explains what the specific problem is – these can be as follows:
Below, we’ll break down each error and some of the most common causes so you can get your site or page back online and working again as quickly as possible.
400 Bad Request errors are usually caused by the request that has been sent to the server either being corrupt or in a format that the server cannot recognise. This can be down to either the data that the browser is sending to the site, or something on the site corrupting the data.
If you’re experiencing this error, you’ll first want to try clearing your browser’s cookies and cache, as the browser may be trying to use an invalid or expired cookie to navigate and log into the site. This then results in the server responding that it does not understand the request. The cookie that your browser has cached may also be corrupt, which could lead to the same result.
If the issue persists after clearing your cache and cookies, it may be something on the website itself. It’s worth disabling any non-critical site plugins or extensions to rule these out, and note any recent changes made prior to the 400 errors cropping up. If the changes were substantial, it may be worth restoring to a backup of the site prior to these changes to see if this reverts the error.
401 Unauthorized occurs when you try to access an area of a site that is being protected by either password encryption or a security rule. Usually, you’ll experience this error if you either try to access an area without providing the necessary login information, or our server’s security blocks the request.
Most commonly, this is due to a site being protected by password requirements set within a .htaccess and .htpasswd file combination. These state that a folder of a site is protected by a specific username and password combination, and any requests made to the site that lack these details will be denied. If you’re experiencing this error, check your site’s .htaccess files to ensure that there’s no set security rules or password protection that could be blocking the request.
Alternatively, the requests could be hitting our StackProtect bot protection. This tool actively filters your site against potentially harmful or suspicious requests, providing a 401 for any request that fails the checks it runs.
However, sometimes these connections can be filtered incorrectly, which is known as a false positive. In cases where your site request is being filtered by StackProtect, you’ll see a message prior to the 401 error stating that the connection is being checked. If this is the case, you should reach out to our Support Team, who can look to get the connection checked and see if we can prevent this being filtered on a case-by-case basis.
A 403 Forbidden error indicates that user trying to access the site does not have the necessary permissions to do so. This can be due to security policies set by the site itself, either through plugins or rules in a .htaccess file, or it can be because the permissions of the site files aren’t set correctly.
If you’re experiencing a 403 error consistently when visiting a website, check the site to make sure that there aren’t any security plugins or addons that could be blocking access to your browser or IP. Also ensure that your site’s .htaccess file doesn’t have any rules that deny access to specific IPs or types of file. If you do, you’ll need to disable or remove these to get the site to be accessible again.
If there aren’t any problems with security rules, then the 403 is most likely being caused by incorrectly set file permissions. File permissions define who can and cannot access certain files, and what services can be used to access them. We have an inbuilt File Permissions Checker that can be used to scan and fix incorrectly-set permissions.
The File Permission Checker is available for all hosting packages via the My20i control panel.
To access this tool:
- Log into My20i and head to your Manage Hosting area
- Select Options > Manage on the hosting package you’d wish to edit
- Head to the Web Files section and select File Permissions Checker
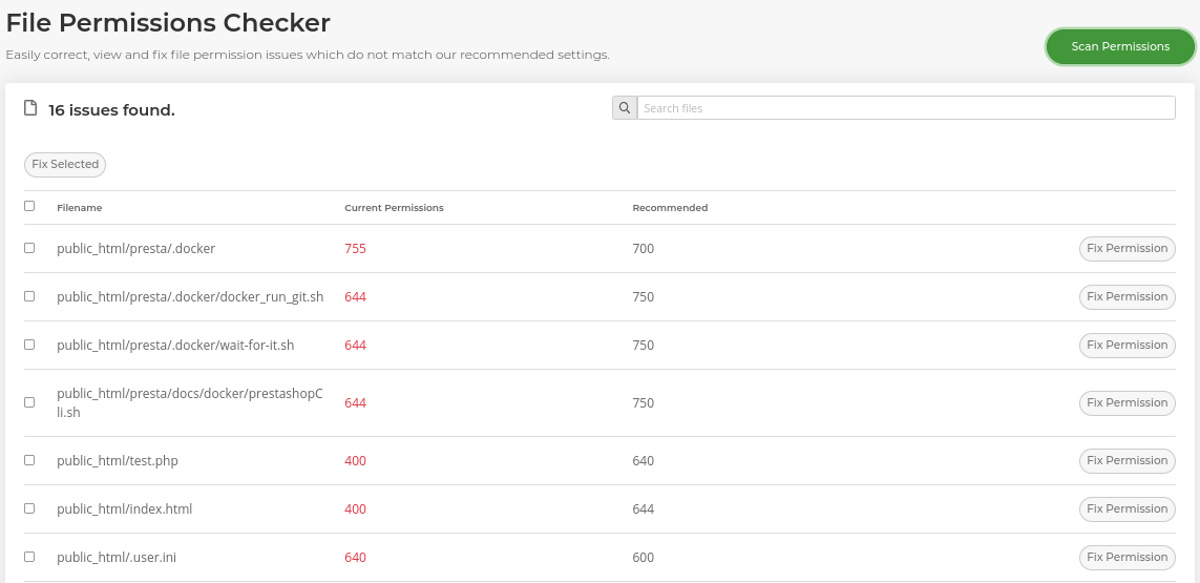
Select Scan File Permissions
Once the scan finishes, check the boxes of any files that are detected to have the wrong permissions, and select Fix Selected to resolve the error.
A 404 Not Found error is caused by the requested page, file or site not being locatable by the server. Usually this is due to the file or page simply not existing on the server itself, or it’s under a different name than the given query. This can often be down to a typo in the URL, which results in the incorrect page or file to be searched for. If you’re experiencing this on your site, it’s worth double-checking to make sure you haven’t made any mistakes when trying to access the page in question.
If it’s not the case, it’s worth checking to see if the requested file does exist on your site. Check your site files: if the file simply isn’t there, you’ll need to upload a copy of the missing file in order to allow it to be accessible once more. Certain Content Management Systems (CMS) such as WordPress use permalinks instead of files per page. These are URLs generated by the site that display a post or page live, rather than storing it locally as a standalone file or folder. If a page within a WordPress site is throwing a 404 but your main site page isn’t, there may be a problem with the generated permalinks, and you’ll need to regenerate them to fix the error.
To do so:
- Sign into wp-admin on your site and head to Settings > Permalinks.
- In the main permalinks area, make sure that the correct value for the URLs is set, and then hit Save Changes. This will force WordPress to fully regenerate the permalink structure and should bring the pages back online once more.
As you can see, 4XX errors come in a wide variety of types and forms, and fixing them can depend on the specific error. If you’re encountering these types of error on your site, it’s worth noting down the specific error code and how you’re accessing the site to get the error. Doing so can help you narrow down and isolate the cause, so you can get your site back online as swiftly as possible.